
突然ですが、皆さん**「ベクトルデータベース」や「RAG(検索拡張生成)」**に対してどんなイメージを持っていますか?
AI界隈のニュースを見ていると、「まるでAIが人間のように文章の意味を理解して、社内ドキュメントから最適な答えを探し出してくれる魔法のシステム」のように語られがちです。 Pinecone、Chroma、Weaviate……次々と新しいSaaSやツールが登場し、フロントエンドエンジニアからすると「また新しい概念を覚えないといけないのか」と、少し辟易している方も多いのではないでしょうか。
しかし、現場で堅実なシステムを組んでいる我々エンジニアにとって、「魔法」という言葉はただの**「ソースコードの未読」**でしかありません。
最近、Cursorやv0を駆使して爆速でプロトタイプを作る「Vibe Coding」がトレンドですが、AIに「よしなに」作らせるためには、我々自身が裏側の仕組みを解剖し、アーキテクチャの急所を握っておく必要があります。 ブラックボックスのままAIにコードを書かせると、あとで取り返しのつかない技術的負債(と高額なクラウドルーターの請求書)を生み出します。
そこで今回は、「魔法のAI検索」ではなく、**「仕様の公開された、ただの配列計算システム」**としてベクトルデータベースを解剖します。 この基礎知識は、あなたが今後AIツールを「使いこなす」ための最強の財産になるはずです。
1. データ構造の正体:ただの「巨大な浮動小数点数の配列(Float Array)」だった
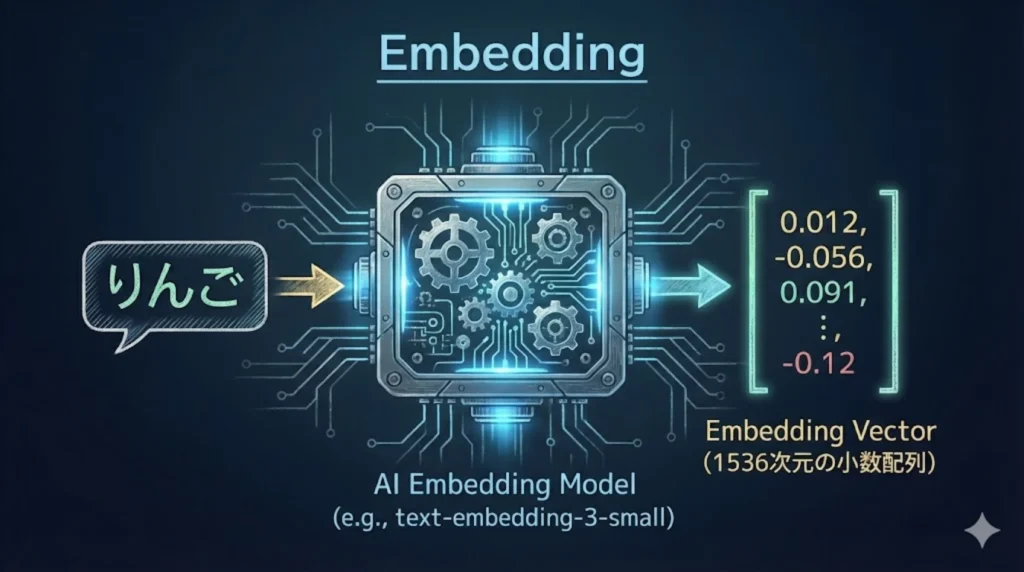
まず、「ベクトル化(Embedding)」という仰々しい名前を剥がしてみましょう。 「文章の意味をベクトル空間にマッピングする」などと小難しく言われますが、我々が普段扱うJSONや配列で表現すると、実体はただの**「小数のリスト」**に過ぎません。
実際に構造をJSONで見てみる
OpenAIの text-embedding-3-small APIなどにテキストを投げたときに返ってくるデータは、以下のような形式です。
JSON
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
0.01234,
-0.05678,
0.091011,
// ... これが 1536個 続く
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}
エンジニアなら一目瞭然ですね。embedding の中身は、1536個の要素を持つただの配列(Array)です。 AIは「りんご」と「みかん」の意味を理解しているわけではありません。「りんご」を入力したときの配列と、「みかん」を入力したときの配列の**「数値的な距離が近い」**というだけです。
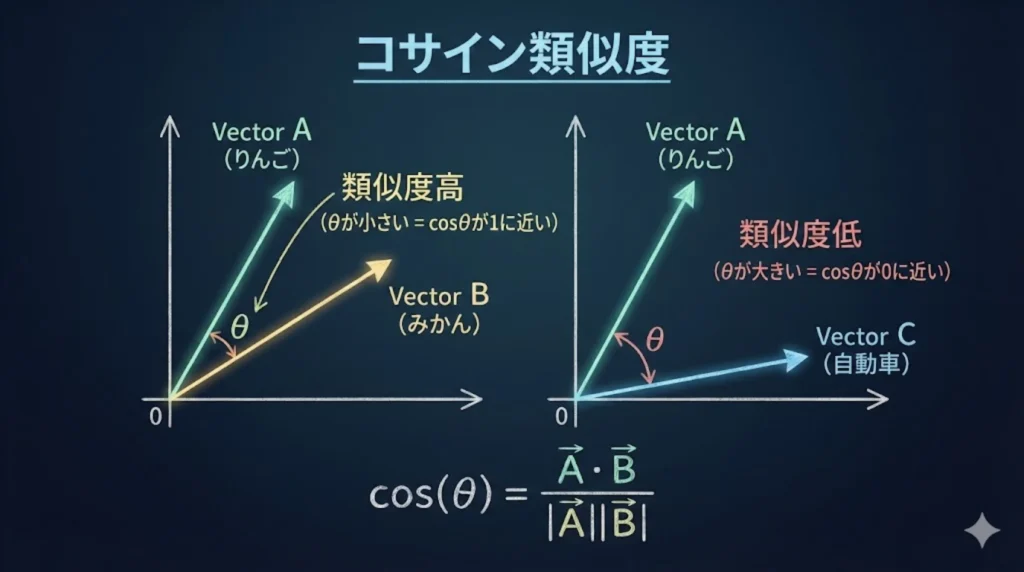
そして「検索」の正体は、中学や高校の数学で習った**「コサイン類似度(Cosine Similarity)」や「ユークリッド距離」**の計算です。 ユーザーが入力した検索クエリを配列に変換し、データベース内の全配列と引き算(または内積計算)をして、結果が「1(完全一致)」に近いものから順番に並べ替えて(ORDER BY)返しているだけなのです。
2. 技術選定の理由:なぜPineconeではなく「PostgreSQL (pgvector)」なのか?
ここで、アーキテクチャ設計における最大の分岐点が訪れます。 「ベクトル検索を実装するなら、Pineconeなどの専用のベクトルDB(SaaS)を使うべきか?」
結論から言うと、我々Studio Puffでは、通常のWebアプリケーション開発において専用SaaSは極力採用せず、**「PostgreSQL + pgvector拡張」**一択としています。
なぜRDB(PostgreSQL)にこだわるのか?
理由は極めてシンプルで、**「データのサイロ化を防ぐため」**です。
専用のベクトルDBを使うと、以下のような地獄の運用が待っています。
- ユーザー情報や記事のメタデータはRDB(MySQLやPostgreSQL)にある。
- ベクトルデータはPineconeにある。
- 「特定のカテゴリ(RDB)の中で、意味が近い記事(Pinecone)を検索する」という処理をしたい場合、アプリケーション側で2つのDBからデータを引いてきて、メモリ上で結合(JOIN)しなければならない。
これはパフォーマンス的にも、トランザクション管理(片方のDBだけ更新に失敗した場合のロールバック等)の観点でも最悪です。
一方、PostgreSQLの拡張機能である pgvector を使えば、いつものSQLで**「メタデータの絞り込み」と「ベクトル検索」を同時に**行えます。
SQL
-- pgvectorを使った実際のクエリ例
SELECT id, title, content
FROM articles
WHERE category_id = 5 -- いつものメタデータ絞り込み
ORDER BY embedding <-> '[0.12, -0.05, 0.09...]' -- コサイン距離演算子で並び替え
LIMIT 5;
インフラがPostgreSQL一つで済むため、運用コストも圧倒的に下がります。Supabaseなどをバックエンドに採用していれば、ボタン一つで pgvector を有効化できるのも大きな魅力です。
3. 現場のリアル:次元数(Dimensions)の不一致とインデックスの罠
しかし、いざ実装に入ると、ベクトルDB特有の泥臭いエラーに直面します。 私がVibe Codingでプロトタイプを組んでいた際、最も時間を溶かした「現場のリアル」を共有します。
ハマりポイント①:次元数の不一致によるクラッシュ
PrismaなどのORMを使って pgvector のスキーマを定義する際、以下のように書きます。
コード スニペット
model Document {
id String @id @default(uuid())
content String
// ここで次元数(1536)を固定する
embedding Unsupported("vector(1536)")?
}
ここで、OpenAIのAPIの仕様変更や、モデルの変更(例:text-embedding-ada-002 から text-embedding-3-large へ変更)を行ったとします。新しいモデルが 3072 次元の配列を返してきた瞬間、データベースへの INSERT は無惨に失敗します。
Bash
# 忌まわしいエラーログ
ERROR: expected 1536 dimensions, not 3072
DETAIL: Vector dimensions do not match the column type.
【ここにCursorのターミナルで吐かれたpgvectorの次元数エラーのスクショを貼る】
通常の文字列や数値なら「型」さえ合っていれば入りますが、ベクトルデータは「配列の長さ(次元数)」がテーブル定義と完全に一致していないと弾かれます。モデルを切り替える際は、DBのマイグレーションが必須になるという強い結合が発生することを覚えておいてください。
ハマりポイント②:IVFFlatの罠と、HNSWによる解決
データが数千件を超えてくると、毎回すべての行と配列の計算をする(Full Scan)とレスポンスが致命的に遅くなります。そこで「インデックス」を張るわけですが、ここで適当に古い記事をコピペして IVFFlat というインデックスを張ると痛い目を見ます。
IVFFlat はデータを「いくつのクラスタ(リスト)に分割するか」を人間が事前にチューニングする必要があり、データ量が増えると精度が急激に落ちるというピーキーな特性があります。
- 解決策: 迷わず
HNSW(Hierarchical Navigable Small World) インデックスを使いましょう。 構築に少し時間はかかりますが、検索速度と精度のバランスが圧倒的に良く、パラメータのチューニングもほぼ不要です。現在のpgvectorのベストプラクティスは間違いなくこちらです。
4. Vibe Codingの財産:基礎を知らないとAIの「嘘」に殺される
ここまでベクトルデータベースの裏側を見てきました。
「なんだ、ただの配列の計算と、次元数を合わせたSQLの実行か」
そう思えたなら、あなたの勝ちです。 冒頭でも触れましたが、CursorなどのAIエディタを使ってVibe Codingをする際、この**「中身はただのDBと配列である」**という基礎知識があるかないかで、生成されるコードの品質が天と地ほど変わります。
もし基礎を知らなければ、AIが「ベクトル検索のために専用のPythonマイクロサービスを立てましょう」と提案してきた時に、素直に従ってしまうかもしれません。 しかし、仕組みを知っていれば、**「いや、バックエンドはSupabaseなんだから、pgvectorを使ってSQLの <-> 演算子で解決するコードを書いて」**と、的確にAIの手綱を握ることができます。
魔法に見える最新技術も、一枚皮を剥けば我々が知っている枯れた技術の組み合わせです。 AIがコードを生成するスピードが限界突破している今だからこそ、我々エンジニアに求められるのは「タイピングの速さ」ではなく、**「生成されたアーキテクチャの妥当性を瞬時にジャッジする、解剖学的な基礎知識」**なのです。
まとめ:AI時代こそ「ブラックボックス」を許すな
いかがでしたでしょうか。 RAGやベクトル検索の実態は、決して意思を持ったAIの魔法ではなく、数学と泥臭いデータベース設計の産物です。
次回の開発で「なんか検索精度が悪いな」と思ったときは、AIのプロンプトをこねくり回す前に、一度DBに入っているベクトルデータ(配列)の次元数やインデックスの張り方、そしてコサイン類似度のSQLクエリを見直してみてください。
【おまけ】Vibe Codingを生き抜くための「現場の用語集」
この記事を読む上で、あるいはこれからのAI開発サバイバルを生き抜くために、バズワードを「エンジニアの現場目線」でざっくり翻訳しておきます。
- Vibe Coding(バイブコーディング) Cursorやv0などのAIツールと対話しながら、ノリと勢い(Vibe)で直感的にコードを組み上げていく最新の開発スタイル。爆速開発が可能になる反面、裏側のアーキテクチャ(今回のようなDBの仕組みなど)を理解していないと、後で手が付けられない「技術的負債」の山を築くことになる諸刃の剣。
- RAG(Retrieval-Augmented Generation / 検索拡張生成) LLMに「自社のマニュアル」や「過去の議事録」といった外部データを検索させ、その結果をもとに回答させる仕組み。要するに**「AIにカンペを読ませてから喋らせる技術」**。この「カンペを探す」部分でベクトルDBが使われる。
- Embedding(エンベディング / ベクトル化) 文章や画像を、AIが処理しやすい「巨大な小数の配列(ベクトル)」に変換すること。
- コサイン類似度(Cosine Similarity) 2つのベクトル(配列)が「どれくらい同じ方向を向いているか」を測る計算式。計算結果が「1」に近いほど、2つの文章の「意味が激似である」と判定される。RAGの検索精度の要。
- pgvector 我らがRDBの王「PostgreSQL」に、ベクトル検索の機能を追加する神・拡張機能。これ一つあれば、高価なAI専用データベースを契約しなくても、いつものSQLで意味検索ができるようになる。
- 次元数(Dimensions) Embeddingによって変換された「配列の長さ(要素の数)」。これがデータベースのテーブル定義と1つでもズレると、容赦なくエラーを吐いてシステムが落ちる。
- HNSW(Hierarchical Navigable Small World) ベクトル検索を超高速化するための「インデックス(目次)」のアルゴリズムの一つ。名前はイカついが、現在のpgvector運用におけるベストプラクティス。
- ハルシネーション(Hallucination) AIが「もっともらしい嘘」を堂々とつく現象。これを防ぐためにRAGを導入するのだが、検索元のベクトルDBの設計が甘いと、結局見当違いなデータを拾ってきてしまい、盛大なハルシネーションを引き起こす。


